Proyectos destacados
Hola y bienvenido a mi portafolio de ingeniería, aquí encontrarás una recopilación de mis 3 proyectos estrella y de los cuales estoy muy orgulloso. El más representativo es Andes Board que me tomó 1 año y 6 meses en construir porque involucraba sensores iot, es una plataforma que le permite a las empresas saber dónde están los cilindros de gas que necesitan reabastecer. Mi segundo proyecto estrella es de machine learning e hice con unos amigos, el objetivo era predecir la calidad de vinho verde. Y como último proyecto estrella, un balanceador de cargas que tiene los desplegues automatizados a la nube de azure.
Si te interesa un proyecto en particular, en el siguiente índice selecciona el proyecto que quieres leer, y te redirigirá a la sección que necesitas.
Índice de proyectos
Monitorea la cantidad de gas en un cilindro de GLP
Este proyecto fue patrocinado por mi anterior trabajo en Andes Technologies, por lo que el código es propiedad intelectual de ellos. Sin embargo, fui autorizado para presentarlo para mi tesis.
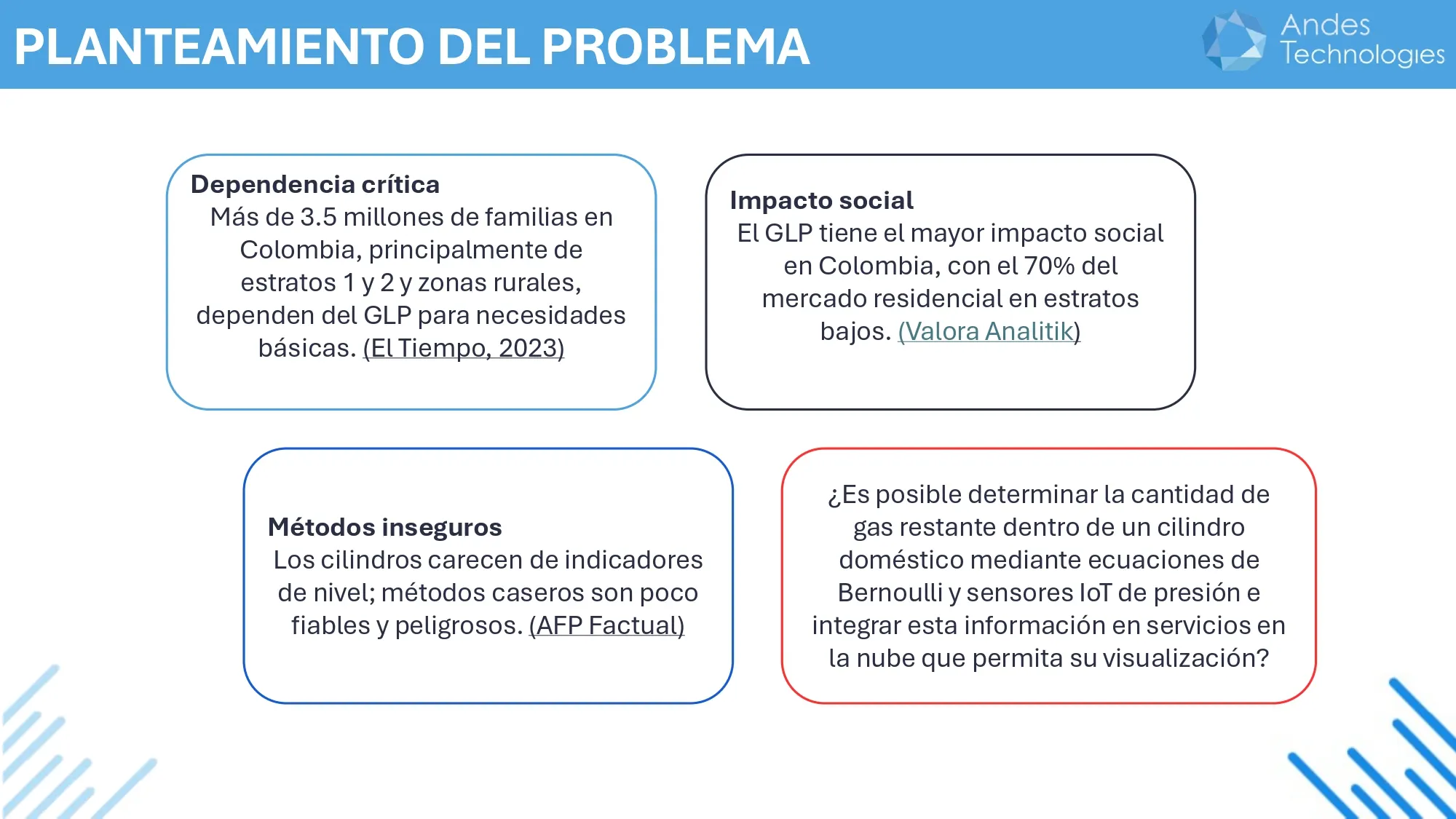
En muchos hogares, los cilindros de gas son necesarios para cocinar u otros usos domésticos. Estos cilindros usualmente no tienen un indicador que muestre cuánto gas les queda. Esto significa que muchas personas se enteran que el gas se acabó cuando la presión del gas baja precipitadamente y el cilindro deja de funcionar. Por eso el proyecto comenzó con una pregunta simple:
¿Es posible saber cuánto gas queda dentro de un cilindro utilizando sensores y algunos cálculos físicos?
Para responder a esta pregunta, desarrollé una app web que combina sensores IoT, mediciones físicas y cálculos matemáticos para determinar el gas restante. La siguiente imagen resume el problema que motivó el proyecto.
Antes de empezar a programar y demás, diseñamos una metodología de investigación para construir y probar los cálculos bajo condiciones controladas que podrás ver más adelante.

Al realizar la metodología de investigación en el escenario que abríamos la válvula y dejábamos escapar el gas, logramos validar que los valores calculados por el sistema eran equivalentes con las mediciones hechas. Pero en otros escenarios, donde el cilindro estaba conectado a una estufa, los cálculos variaban mucho. Y tras muchos intentos llegamos a las ecuaciones de flujo crítico y subcrítico que variaban poco en el escenario del cilindro conectado a una estufa.

Diseño de la app
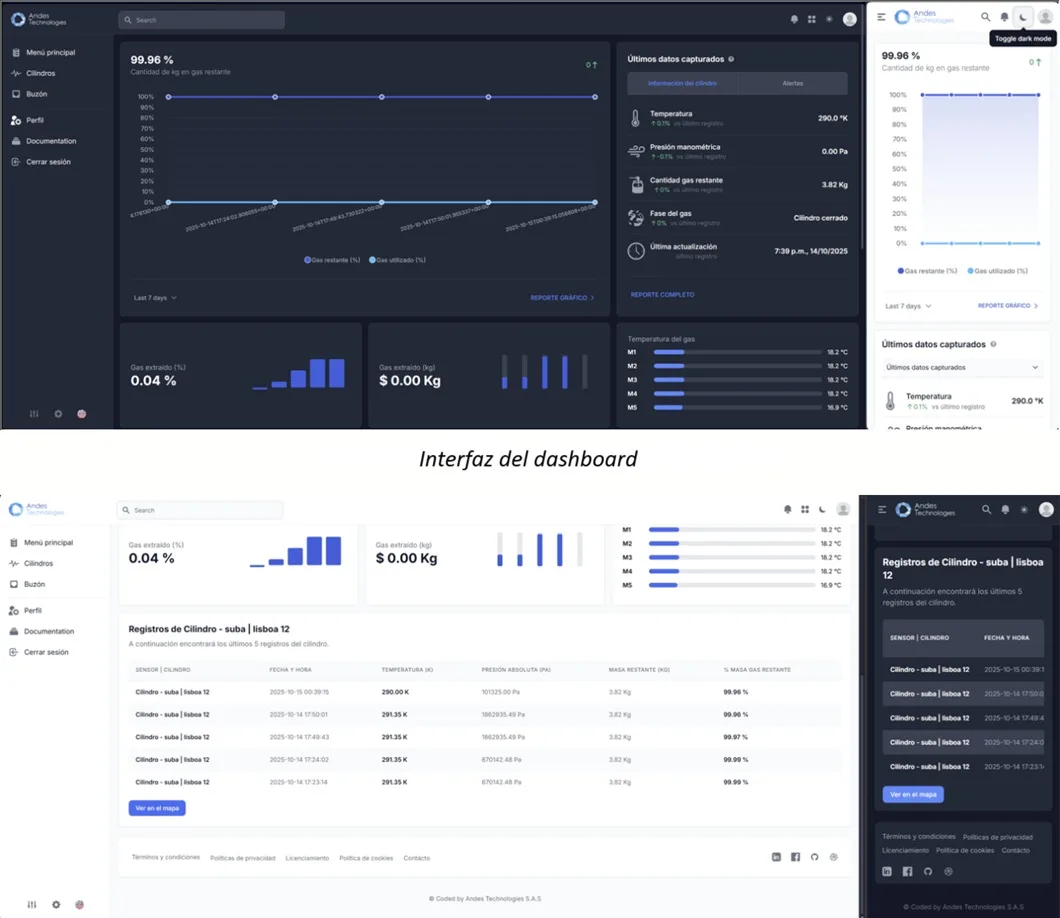
Para mostrar los resultados de la fase anterior desarrollamos un sistema que se conecta a los sensores IoT TP2401 a través de multiples APIs, procesaba los datos y mostraba los datos en un dashboard para mostrar los resultados. Este dashboard permite monitorear variables como la presión, la temperatura, el caudal, las estimaciones de gas restante y la ubicación en tiempo real.
Conclusiones
Las pruebas demostraron que es posible determinar con alta precisión la cantidad de gas que sale del cilindro utilizando mediciones físicas y cálculos matemáticos, siempre y cuando no se acumule en la válvula de salida o esté conectado a un electrodoméstico porque el sensor puede interpretar ese gas acumulado como si estuviera fluyendo constantemente hacia afuera.
En este escenario, el sistema puede sobreestimar la tasa de salida de gas, introduciendo errores en los cálculos. Por lo que, para mejorar la precisión, este tipo de sensores deberían integrarse directamente en los electrodomésticos que consumen el gas
Si quieres leer más, haz clic aquí →
02. Predicción de la calidad del "Vinho Verde" con Machine Learning
Este fue un proyecto universitario que nos puso a mis amigos y a mí en aprietos: teníamos solo tres meses para desarrollar un algoritmo supervisado de Machine Learning en R. El primer reto a superar era que ninguno de nosotros había usado R antes; así que tocaba aprender sobre la marcha. Lo que no sabíamos era que el reto tenía implantada una trampa desde el comienzo.
1. El desafío de los datos y la no linealidad
La Universidad de Minho en Portugal creó un dataset en 2009 evaluando la calidad del Vinho Verde al noroeste del país. Tomaron muestras de productores locales y las enviaron a laboratorios para realizar pruebas fisicoquímicas. Luego, los investigadores crearon bases de datos y modelos usando redes neuronales probabilísticas, utilizando la técnica de perceptrón multicapa y máquinas de soporte vectorial. Nosotros no supimos del artículo sino días posteriores de haber terminado el proyecto, porque el reto planteado en la clase era usar regresión lineal para obtener un coeficiente de determinación (R²) no menor al 70%.
Antes de pensar en entrenar al modelo, hicimos minería de datos para detectar valores que pudieran dañar el modelo. Y luego mediante la correlación de Spearman evaluamos qué tan relacionadas estaban las 20 variables con la calidad. Pero cuando vimos los QQ Plots, nos dimos cuenta de que ninguna variable predictora seguía una tendencia lineal clara respecto a la variable objetivo, la calidad.
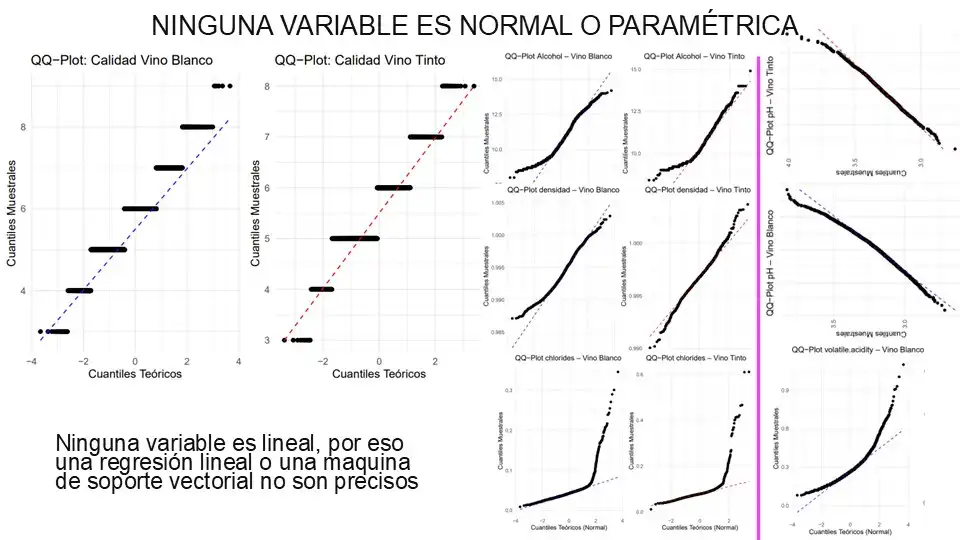
2. Procesamiento y normalización
Nuestro sentido arácnido se activó, pero no podíamos retroceder; ya llevábamos un mes aprendiendo R y aún desconocíamos el paper original. Para reducir el ruido usamos el método de Anderson-Darling. Elegimos 11 variables que seguían mostrando índices no paramétricos que no seguían una distribución normal. Y para confirmamos una vez más que la regresión lineal es poco viable usanmos gráficos de asimetría y curtosis para ver cómo las colas imposibilitaban el análisis. Pese a las evidencias, decidimos continuar con la regresión porque eran instrucciones de la profesora, y pensábamos que ella no podía estar equivocada.
Luego, intentamos normalizar las 11 variables predictoras para que el modelo hallara una linealidad en 11 diferentes dimensiones usando la librería bestNormalize. Sin embargo, ninguna transformación fue capaz de estabilizar los datos.
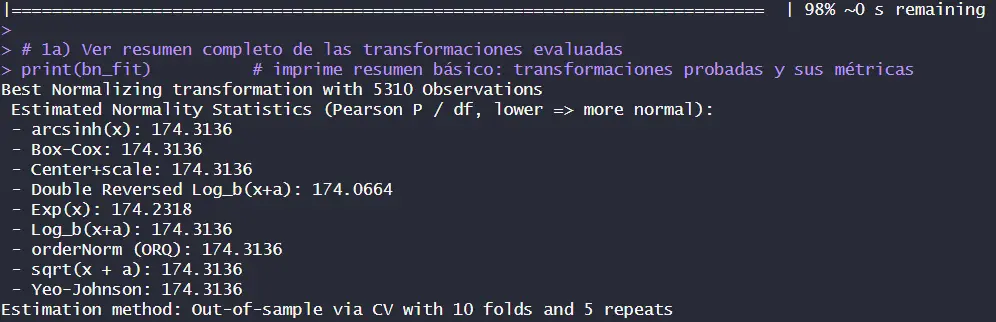
3. Desarrollo del modelo
El reto final
Quedaban dos semanas para lograr que un modelo de regresión lineal predijera la calidad del vinho con un 70% de precisión. Pero tras horas y horas de ajustes, no superábamos el 30.8%. Allí descubrimos que el 28% de esa predicción se debía únicamente al alcohol; las otras 10 variables juntas solo aportaban un 2.8% Y la ecuación polinomial que se obtuvo fue esta:
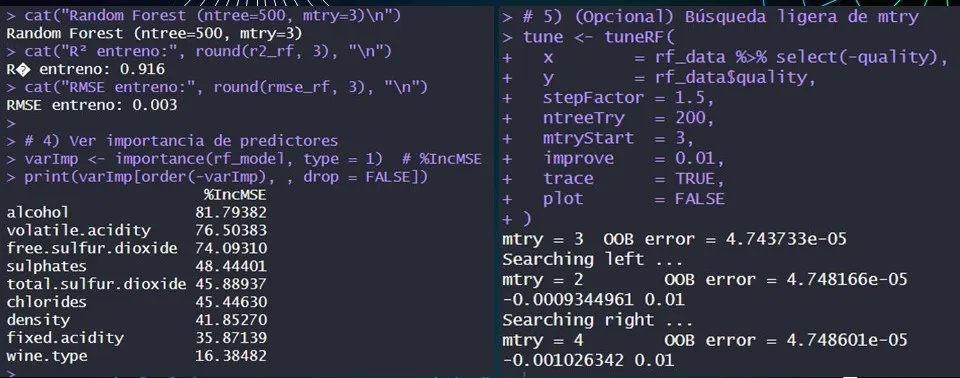
A solo un día de entregar un modelo que fallaba estrepitosamente, un buen amigo de otro grupo, John Valderrama, nos recomendó usar el algoritmo de bosques aleatorios. Y tras estudiarlo y configurarlo, milagrosamente logramos predecir el 91.6% de la calidad del vino. También probamos máquinas de soporte vectoria, que solo alcanzó un 41.1%, quizás porque el estudio original de la Universidad de Minho usaba desviación absoluta y nosotros buscábamos el coeficiente de determinación.
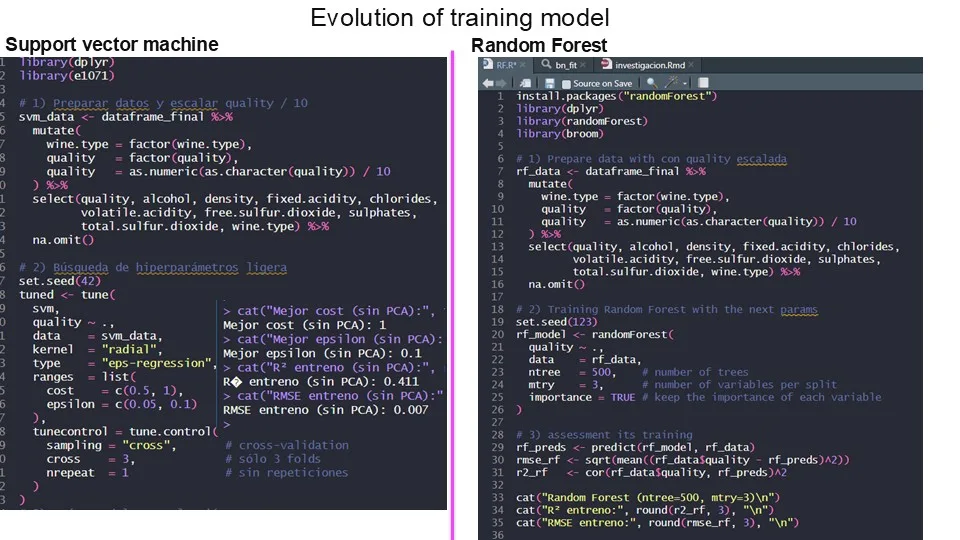
4. Evaluación y Resultados: Alcanzando un 91.6% de precisión
- El análisis reveló que por cada aumento de 1% en el contenido de alcohol, la calidad del vino incrementa en 0.305 puntos en promedio (controlado por las demás variables). Y junto a su resultado en el test de Anderson-Darling, el alcohol tiene un impacto positivo y real sobre la calidad del vinho. Así que ya saben: entre más alcohol, más sabroso será su vinho.
- El modelo identificó qué componentes influyen más; el polinomio de primer grado detallado arriba tiene ordenadas de mayor a menor las variables según su impacto en la calidad percibida.
- Por último, pero no menos importante: sin el apoyo de mis amigos no hubiera logrado culminar este proyecto. Esto fue posible gracias a que Carlos Mahecha y Sebastián Ramírez hicieron todo lo necesario para que el proyecto funcionara.
Explorar el repositorio y la investigación detallada →
03. Arquitectura DevOps, ci/cd y balanceo de carga en Azure
Este proyecto nació de una necesidad de aprender Docker. En navidad de 2024 y a comienzos de 2025, mi cabeza solo pensaba en: necesito aprender Docker para implementarlo en mi tesis, por lo que estaba tomando cursos en Platzi. Como los cursos eran tan nuevos, yo terminaba siendo el primer comentario en todas las clases. Lo curioso es que, a día de hoy, todavía hay personas dándole like o agradeciéndome por esos aportes. Esa comunidad me inspiró a compartir todo lo que sé y a aportar a la comunidad del software.
El reto era dejar las apps web listas para enviar a producción con pocos clicks, y para eso los contenedores tenían que ser ligeros y escalables usando la técnica de múltiples capas y, lo integré con github para crear un flujo ci/cd que cubre desde la optimización de imágenes hasta la orquestación en la nube, usando GitHub Actions, Nginx y Microsoft Azure.
1. Estrategias de contenedores para producción
En producción, un contenedor debe ser liviano y seguro. No se pueden subir imágenes pesadas y vulnerables. Por eso, implementé dos estrategias según lo que necesitaba el servicio:
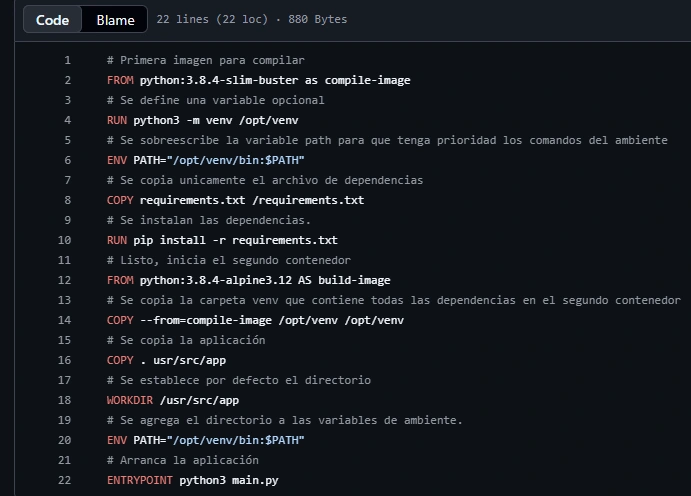
Construcción de contenedores multietapa
Es muy útil cuando el contenedor necesita compilar dependencias pesadas la imagen a construiry luego movemos los binarios finales a una imagen ultra ligera. Así, el servidor de producción no carga con basura innecesaria.
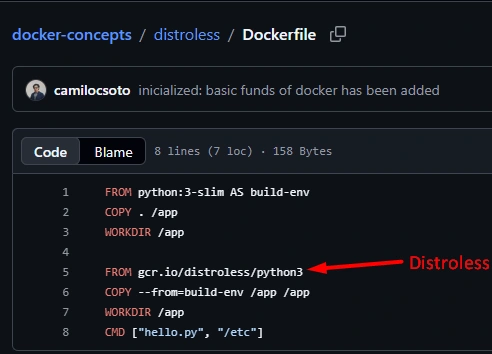
Imágenes distroless
Este lo usé para un docker que solo necesitaba mostrar una app web estática y al quitar el sistema operativo, gestores de paquetes una terminal activa podía ser insegura quita una gran cantidad de peso y reduce mucho la superficie de ataques y consumo de recursos.
2. Automatización con ci/cd en GitHub actions
Para hacer más fáciles los despliegues a internet, configuré archivos .yml para que pipelines de integración y despliegue Continuo automatice eso; la idea es simple, yo hago git push y el despliegue se haga solo.
Cada vez que subo cambios al repositorio, GitHub Actions despierta, construye las imágenes optimizadas y las empuja a DockerHub para registrar artefactos y a Azure para que se actualicen.
3. Alta disponibilidad y balanceo de cargas
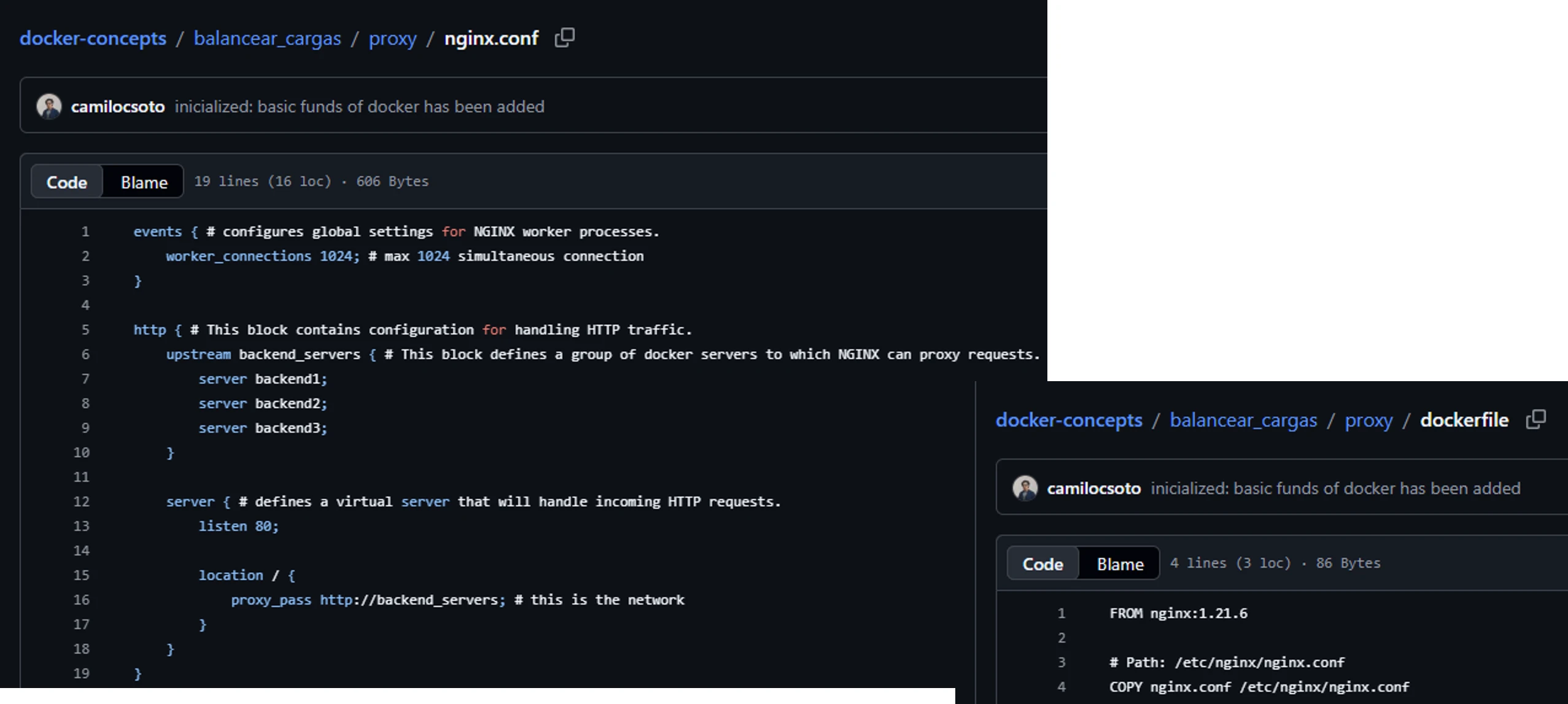
Y para terminar, hice mi propio balanceador de cargas y lo configuré con Nginx actuando como proxy inverso para entender cómo funcionan los kubernetes, aunque aún no he aprendido a usar k8s.
Para lograrlo, en lugar de usar un solo servidor, dejé varios contenedores expuestos con el mismo contenido, y el archivo nginx.conf distribuye el tráfico entre todos los contenedores web. Si uno colapsa por la cantidad de solicitudes, los otros tres siguen respondiendo sin que el usuario note absolutamente nada.
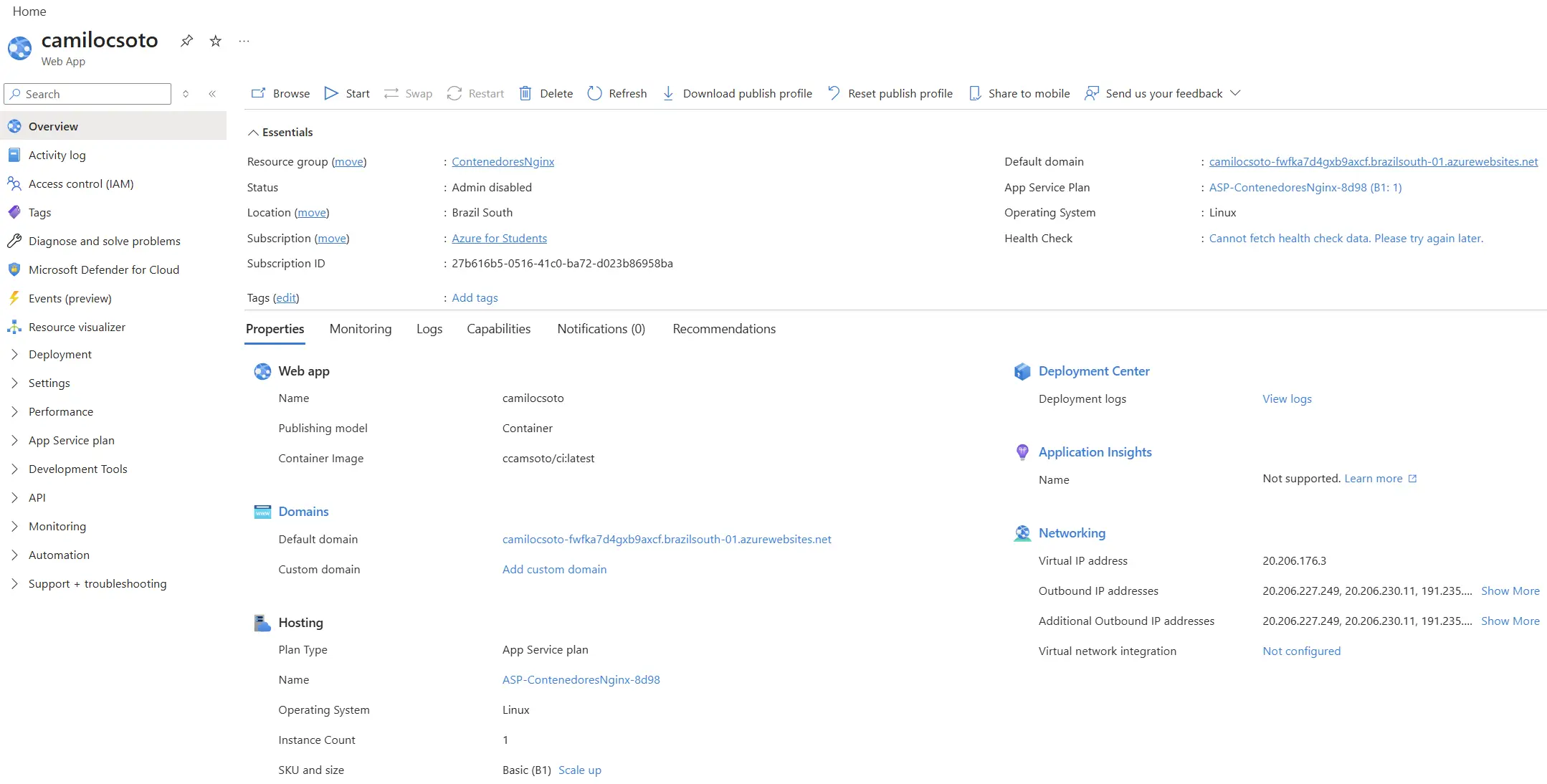
4. Despliegue final en la nube
Todo el balanceador lo desplegué en Azure web services. el servicio principal y la red interna que comunica los contenedores. Aunque posteriormente tuve que apagarlo porque se acabaron todos mis créditos y mantener el servicio activo termina siendo algo costoso.
Si quieres ver los Dockerfiles y archivos de configuración, revisa mi GitHub aquí →